[딥러닝] 9장 최근 언어 모델
9장 최근 언어 모델
1. Parameter-Efficient Training
1. Parameter-Efficient Fine-Tunning (PEFT)
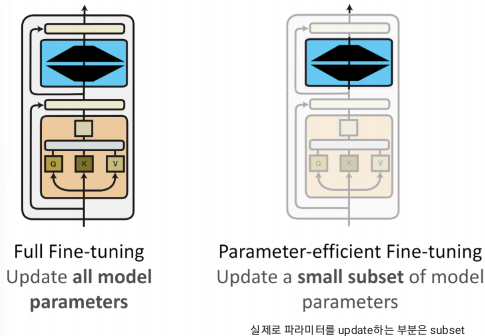
main idea: 조금의 파라미터만 업데이트 하자!
- 모든 파라미터를 파인튜닝하는 것은 비실용적!
- 요즘 모델들 파라미터 너무 많음. → 사실 parameter-efficient fine tunning해도 성능 비슷
요즘의 AI paradigm은 Efficiency 보다 정확도에만 집중함.
그러나 Efficiency도 중요하다!
2. Parameter Efficient Full-Finetunning
문제점:
GPT-3은 1750억 개의 파라미터를 가지고 있음.
너무 많은 비용이 들어!
Main idea:
원래 가지고 있던 파라미터 |ϕ|를 더 작은 크기의 파라미터인 |Θ|로 인코딩함.
따라서 task별로 전체 모델을 다시 훈련시키는게 아니라 작은 세트인 Θ 파라미터만 조정하면 됨.
기존 파라미터를 찾는 작업은 이제 Θ를 최적화 시키는 문제가 됨!

3. Adapter vs LoRA


**LoRA 시험에 내기 좋다!!** - 계산 방법, 동작 과정, 장단점...
LoRA는 PEFT 방법 모델 중 하나!
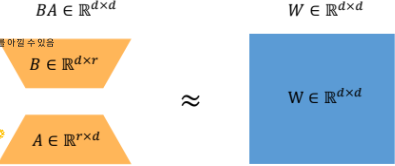
d가 10일때 기존에는 100개의 파라미터를 써야했지만,
adapter를 사용하면, d=10, r=2일 때 , 40개의 파라미터만 사용해서 업데이트 시키면 됨.
여기서 학습되는 것은 B와 A만임!!!
task할 때마다 주황색 부분의, 즉 B와 A만 갈아 끼워넣으면 여러 task에 사용할 수 있음 - plugin 방법!
이렇게하면 추가적인 추론 지연이 발생하지 않음!
LoRA성능
(좌) 쿼리와 벨류 레이어에 LoRA를 넣는 것이 효율적.
(우) r값 즉, rank에 따라 성능이 다르다!


2. Neural Information Retrieval
1. 정보검색을 위한 딥러닝 진화

2. Traditional Search에서의 검색 결과 띄우는 과정
① Crawling
고려할 점
- Redirection - 여러번의 redirection이 나오면 데드락 같은 문제 초래할 수
- 중복된 content
- content 품질 - gpt가 만들었거나 품질 낮은거 ㄴㄴ
- 핵심 문서가 있어야 함.
② Indexing
크롤링해서 얻은 문서들을 indexing함.
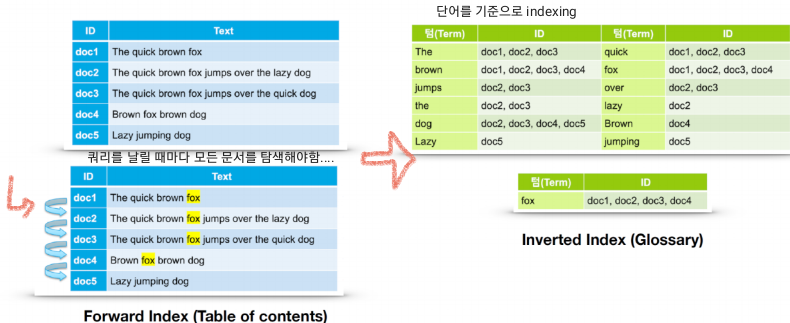
고려할 점
- 어떤 단위의 단어를 선택할거냐
- 각각의 idex가 유사한 용어 분포를 가져야 함.
③ Ranking
<<First-stage retrieval>>
BM25 알고리즘: weight를 따져서 높은 weight를 가진 doc을 가져오자!
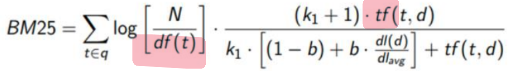
<<Second-stage reranking>>
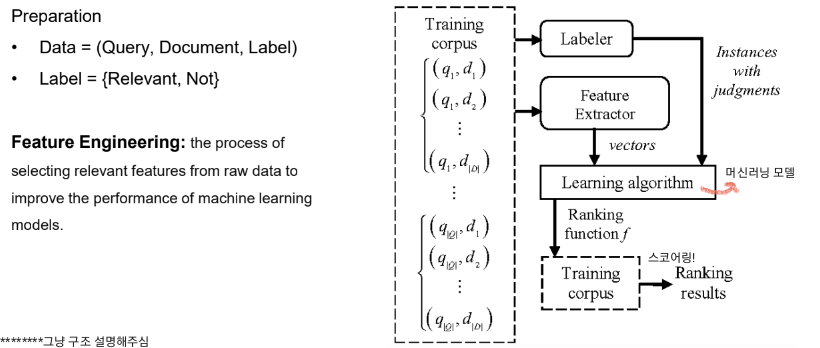
ex. BM score가 높은 문서 k개를 고르고 난 뒤, 한번 더 reranking하여 상위 N개 문서 결정
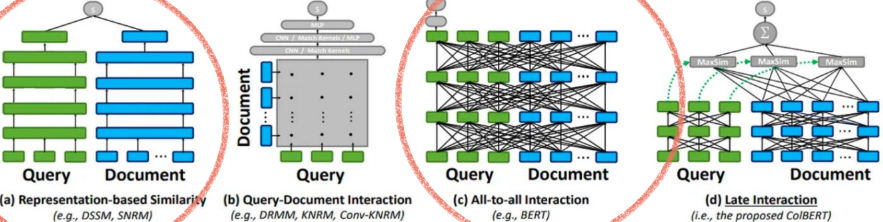
- Representation-based Similarity: 쿼리는 실시간으로 인코딩하고, 문서는 이미 인코딩 되어있어, 두 벡터의 유사도를 계산하는 방식
- Query-Document Interaction: 여러 문서 간의 사호작용을 고려해 랭킹 매김.
- All-to-all Interaction: 쿼리와 모든 문서간의 상호작용을 고려.(ex. BERT)
- Late Interaction: 따로 인코딩하다가 최종적으로 문서와 쿼리의 상호작용을 고려
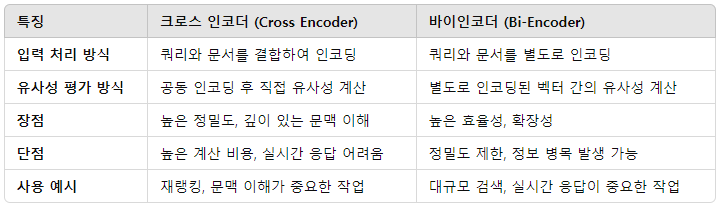
3. Bi-Encoder & Cross-Encoder
BERT
- pretrained BERT - 단어와 문장을 표현할 수 있음.(embedding 모델)
- Fine-Tunning BERT?
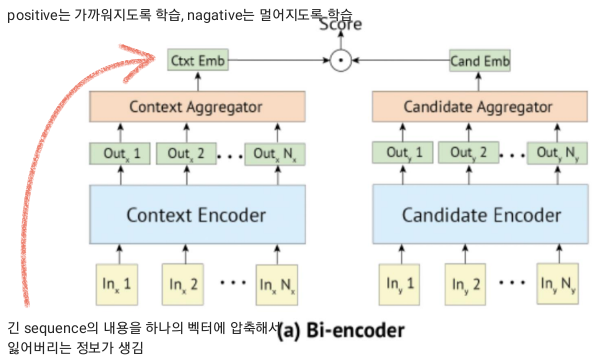
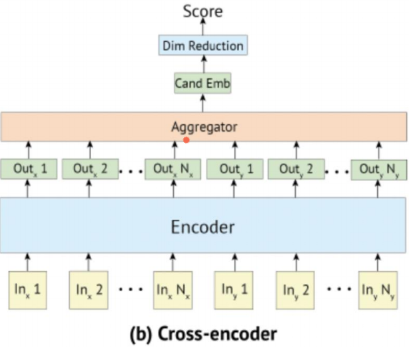
Bi-encoder의 context encoder에는 쿼리가, candidate encoder에는 문서가 들어가서 인코딩됨.
Cross-encoder의 성능이 더 좋음!
어쨋든 둘 다 reranking에 사용됨으로 점수를 출력함.
+) IR Datasets - ex. MS MARCO Web Search dataset
3. Retrieval-augmented LLM
1. Retrieval-augmented LLMs
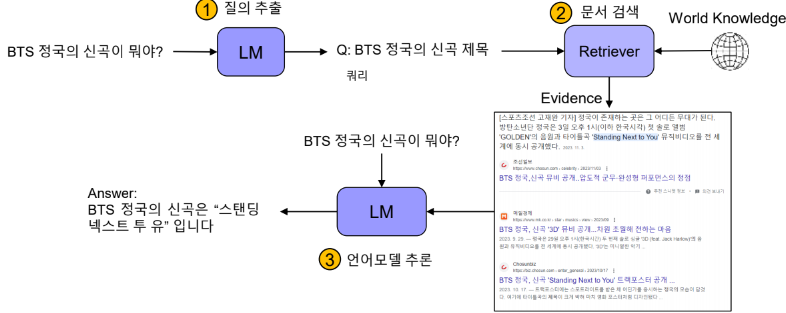
Retrieval-augmented LLM = 검색 증강 언어모델
: 언어모델에 질문과 더불어 검색엔진 결과를 함께 이용
2. Retrieval-augmented LLM의 장점(3)***
- 파라미터 효율성
- 기억을 위한 더 적은 파라미터 필요
- 더 투명하고, 더 해석 가능함
- 예측의 지식 출처를 찾기 쉬움
- 지식을 더 쉽게 업데이트 가능
- 모델 재훈련이 필요 없음.
3. Retrieval-augmented LLM의 도전 과제(4)***
- 컨텍스트 구성을 어떻게 해야하는가
- 예: 6개의 텍스트 패시지, 각 패시지는 1-2문장.
- 긴 문서가 필요한 복잡한 질문에 대한 해결책: LLM의 컨텍스트 길이를 늘리기.
- RAG 결과는 검색 모델의 성능 의존:
- 검색 노이즈가 Hallucination을 증가시킬 수 있음.
- 해결책: 노이즈와 함께 훈련.
- LLM의 사전 지식과 컨텍스트 간의 충돌:
- 예: EPL에서 가장 높은 연봉을 받는 선수에 대한 질문에서 사전 지식과 실제 컨텍스트의 답변 충돌.
- 해결책: 컨텍스트 기반 학습 강화.
- 복잡한 추론이 필요하거나, 문서가 명백한 사실에 대해 오류를 포함할 때