0. 물리적 데이터베이스 설계
- 논리적인 설계의 데이터 구조를 보조 기억 장치 상의 화일로 사상함.
6-1 보조 기억 장치
1. 보조 기억 장치
- DBMS는 사용자가 원하는 데이터를 포함하고 있는 블록을 디스크에서 주기억장치로 가져와야함.
- 데이터가 변경된 경우 블록들을 디스크에 다시 기록.
- 보통 블록의 크기는 4,096바이트.
- 각 화일은 고정된 크기의 블록들로 나누어져서 저장됨.

- 디스크
- 디스크는 데이터베이스를 장기간 보관해주는 보조 기억 장치.
- 전체 데이터베이스가 디스크에 저장됨.
- 컴퓨터 시스템이 다운되는 경우에도 디스크의 데이터베이스는 손상 안됨.
- 직접 접근 장치이므로, 디스크 상의 임의의 위치에 있는 데이터를 바로 접근할 수 있음.
디스크에서 임의의 블록을 읽거나 기록하는데 걸리는 시간 = 탐구시간 + 회전지연시간 + 전송시간
- 탐구 시간(seek time) = 원하는 실린더 위에 디스크 헤드가 놓일 때까지의 시간.
- 회전 지연 시간(rotational delay) = 원하는 블록이 디스크 헤드 밑에 올 때까지 걸리는 시간.
- 전송 시간(transfer time) = 블록을 주기억 장치로 전송하는데 걸리는 시간.


- 자기 테이프
- 데이터베이스를 백업하기 위해서 사용.
- 순차 접근 장치이므로, 디스크 장치보다 속도가 느림.
6-2 버퍼 관리와 운영 체제
1. 버퍼 관리와 운영 체제
- 디스크 입출력은 컴퓨터 시스템에서 가장 속도가 느린 작업.
- 따라서 입출력 횟수를 줄이는 것이 DBMS 성능 향상에 매우 중요!
- 가능한 많은 블록들을 주기억 장치에 유지하거나,
- 자주 참조되는 블록을 주기억 장치에 유지하면 블록 전송 횟수 줄일 수 있음.
- 버퍼: 디스크 블로글을 저장하는데 사용되는 주기억 장치 공간.
- 버퍼 관리자: 운영체제의 구성요소. 주기억 장치 내에 버퍼공간을 할당하고 관리함.
- (운영체제에서 사용하는 LRU 알고리즘은 데이터베이스에서는 우수한 성능을 보이지 않음.)
6-3 디스크 상에서 화일의 레코드 배치
1. 디스크 상에서 화일의 레코드 배치
<<화일과 블록과 레코드>>
- 애트리뷰트들은 필드로 표현됨.
- 연관된 필드들이 모여 레코드가 됨.
- 한 릴레이션을 구성하는 레코드들의 모임이 화일에 저장됨.
- 화일은 블록들의 모임임.

<<디스크에서 블록들의 연결>>
- 한 화일에 속하는 블록들이 반드시 인접할 필요는 없음.
- 인접한 블록을 읽는 경우 탐구 시간과 회전 지연 시간이 들지 않음.
- 따라서 블록들이 인접하도록 한 화일의 블록들을 재조직 할 수 있음.

2. BLOB과 채우기 인수
<<BLOB>>
: BLOB으로 선언된 애트리뷰트는 이미지, 동영상 등의 대규모 크기의 데이터를 저장하는데 사용.
<<채우기 인수>>
: 각 블록에 레코드를 채우는 공간의 비율.
- 한 블록에 레코드를 가득 채우지 않고 빈 공간을 남기는 이유:
레코드가 삽입될 때 기존의 레코드들을 이동하는 가능성을 줄이기 위해.

3. 고정 길이 레코드
: 레코드 길이가 n바이트인 고정 길이 레코드에서 레코드 i에 접근 하려면
"n * ( i - 1 ) + 1"의 위치에서 레코드를 읽음.
아래의 경우에서 세번째 레코드에 접근하려면 "18*2+1= 37" 37바이트부터 18바이트 읽으면 됨.

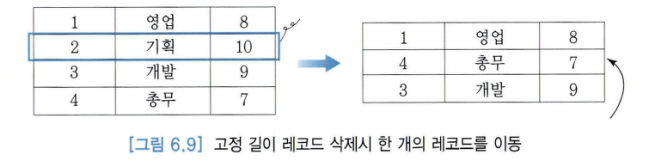
- i번째 고정길이 레코드를 삭제할 때 i+1, ...,n번째 레코드를 i,...,n-1번째 레코드로 하나씩 이동하면 아래와 같다.
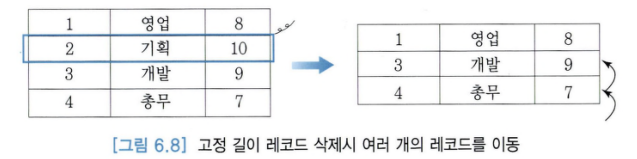
- n번째 레코드를 바로 i번쨰 자리로 옮기면 속도가 더 빨라진다.
- 고정길이 레코드의 예시

4. 화일 내의 클러스터링
(1) 화일 내의 클러스터링(intra-file clustering)
: 함께 검색될 가능성이 높은 레코드들을 디스크 상에서 물리적으로 가까운 곳에 모아두는 것.
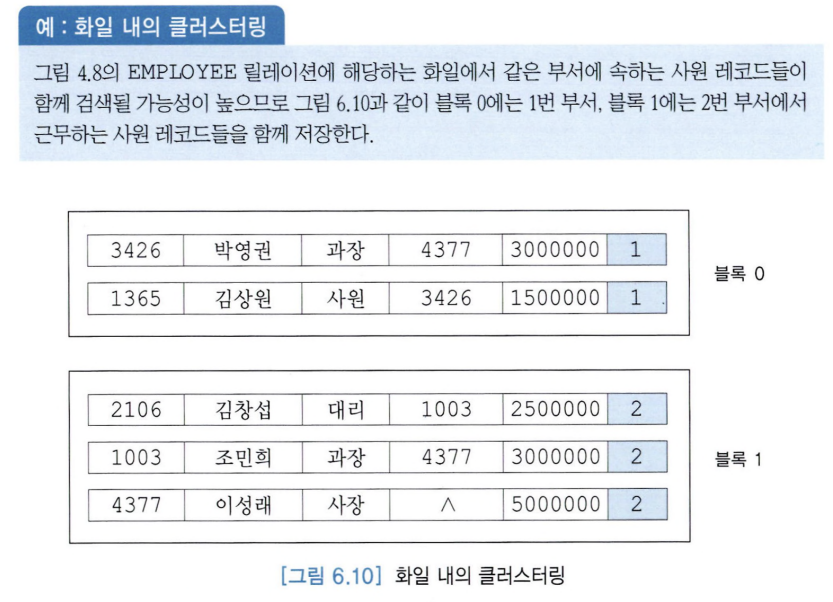
(2) 화일 간의 클러스터링(inter-file clustering)
: 함께 검색될 가능성이 높은 두 개 이상의 화일에 속한 레코드들을 디스크 상에서 물리적으로 가까운 곳에 저장하는 것.
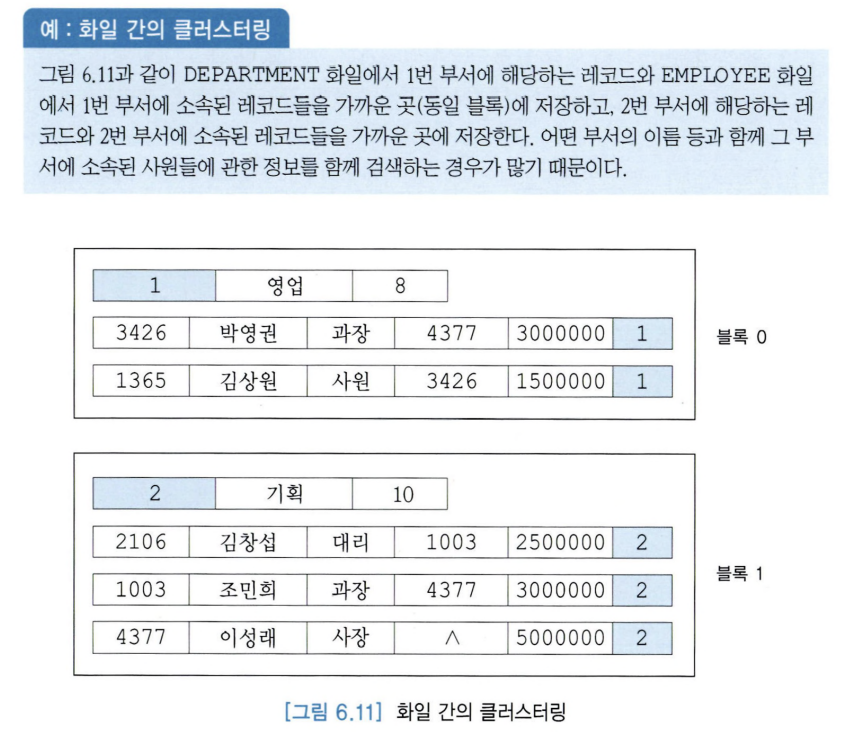
6-4 화일 조직
0. 화일 조직의 유형
- 히프 화일
- 순차 화일
- 인덱스된 순차 화일
- 직접 화일
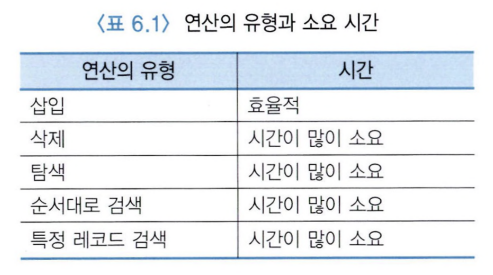
1. 히프 화일(heap file, 비순서 화일)
- 가장 단순한 화일 조직
- 삽입: 새로 삽입되는 레코드는 화일의 가장 끝에 첨부.
- 검색: 모든 레코드들을 순차적으로 접근.
- 삭제: 원하는 레코드를 찾은 후 그 레코드를 삭제함. 삭제된 레코드가 차지하던 공간을 재사용 안함.
- 좋은 성능을 위해 주기적으로 재조직할 필요가 있음.
- 효율적인 상황: 모든 레코드들을 참조하고, 레코드들을 접근하는 순서는 중요하지 않을 때.
- 비효율적인 상황: 특정 레코드를 검색하는 경우.

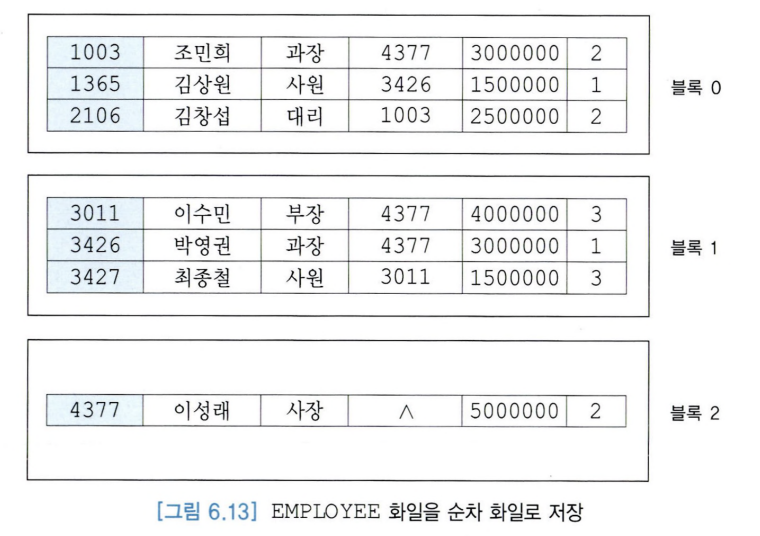
2. 순차 화일(sequential file, 순서 화일)
- 레코드들의 하나 이상의 필드 값에 따라 순서대로 저장된 화일.
- 탐색 키 값의 순서에 따라 저장됨.
- 탐색 키: 순차 화일을 정렬하는데 사용되는 필드.
- 삽입: 레코드 순서를 고려해야해서 시간이 많이 걸릴 수 있음.
- 삭제: 빈 공간으로 남겨 히프 화일처럼 주기적으로 재조직해야함.
- 기본 인덱스가 순차 화일에 정의되지 않는 한 순차 화일은 거의 사용 안함.
- 탐색 키와 연관된 레코드를 찾을 떄는 이진탐색을 이용할 수 있음.

6-5 단일 단계 인덱스
1. 단일 단계 인덱스
- 인덱스된 순차 화일:인덱스를 통해 임의의 레코드를 접근할 수 있는 화일
- 단일 단계 인덱스의 각 엔트리: <탐색 키, 레코드에 대한 포인터>
- 인덱스는 데이터 화일과 별도의 화일에 저장됨.
- 인덱스의 크기는 데이터 화일의 크기에 비해 매우 작음.
- 하나의 화일에 여러 개의 인덱스 정의 가능.
- 오름차순으로 정렬.
- 인덱스가 정의된 필드를 탐색 키라고 부름.
- 탐색 키의 값들은 튜플마다 반드시 고유하지는 않음.
- 어떤 애트리뷰트도 탐색 키로 사용 가능.
- 인덱스의 엔트리들은 오름차순으로 저장되어 있으므로, 이진 탐색을 이용할 수 있음.

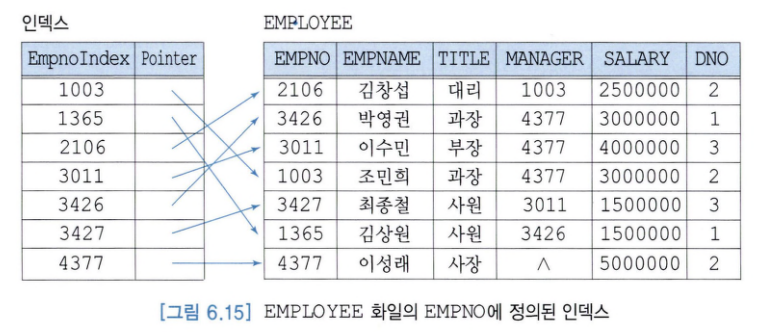
2. 기본 인덱스
: 탐색 키가 데이터 화일의 기본 키인 인덱스.
- 희소 인덱스로 유지할 수 있음.
- 각 릴레이션마다 최대 한 개의 기본 인덱스를 가질 수 있음.
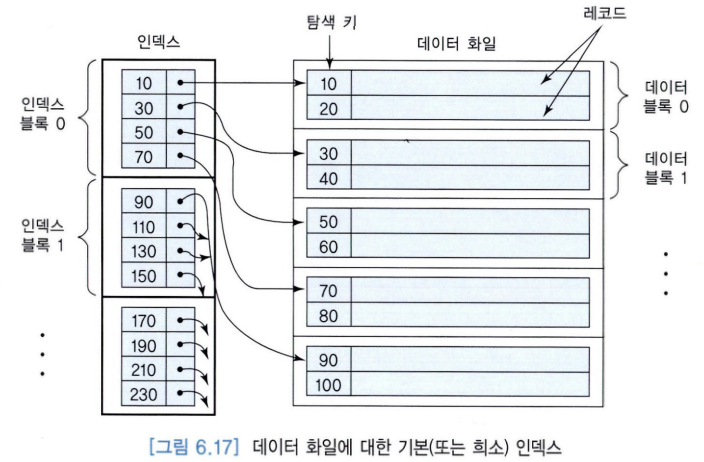

3. 클러스터링 인덱스
- 범위 질의에 유용.
- 범위의 시작 값에 해당하는 인덱스 엔트리를먼저 찾고, 범위에 속하는 인덱스 엔트리들을 따라가며 레코드를 검색.
- 어떤 인덱스 엔트리에서 참조되는 데이터 블록을 읽어오면, 그 데이터 블록에 들어 있는 대부분의 레코드들은 범위 만족.
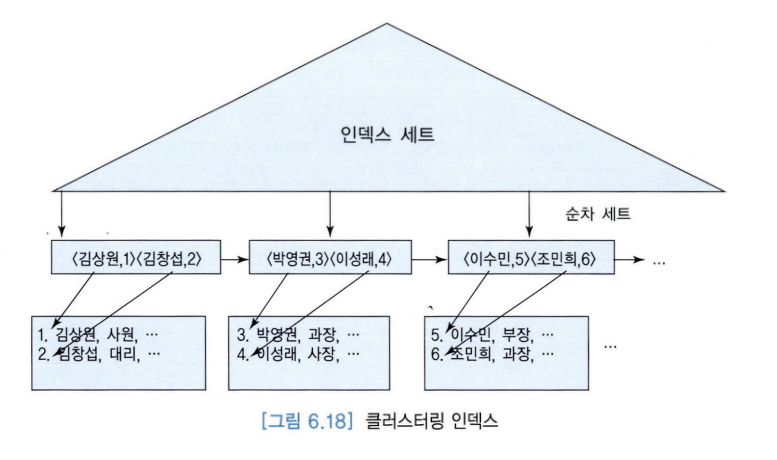


4. 보조 인덱스
- 탐색 키 값에 따라 정렬되지 않은 데이터 화일에 대해 정의됨.
- 기본 인덱스 이외의 인덱스임.
- 기본 인덱스 - 신용카드 번호
- 보조 인덱스 - 사용자 이름
- 보조 인덱스는 일반적으로 밀집 인덱스이므로, 같은 수의 레코드들을 접근할 때 보조 인덱스를 통하면, 기본 인덱스를 통하는 경우보다 디스크 접근 횟수가 증가할 수도 있음.
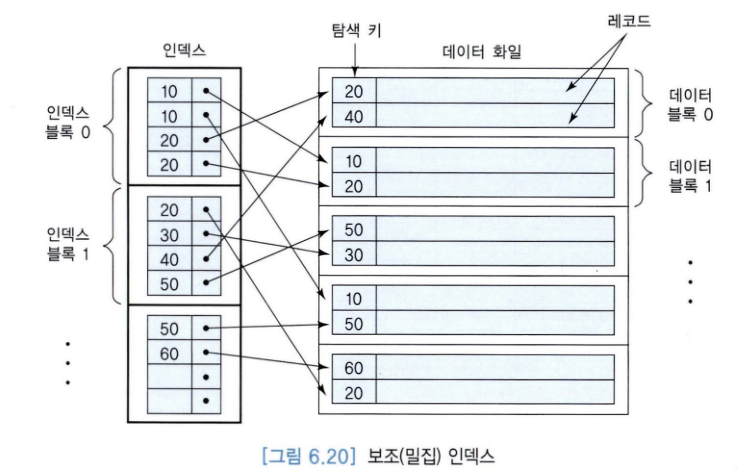
5. 희소 인덱스
: 일부 키 값에 대해서만 인덱스에 엔트리를 유지하는 인덱스.
일반적으로 각 블록마다 한 개의 탐색 키 값이 인덱스 엔트리에 포함됨.
(희소 인 덱스의 그림은 기본 인덱스의 그림을 참조)
6. 밀집 인덱스
: 각 레코드의 키 값에 대해서 인덱스에 엔트리를 유지하는 인덱스.
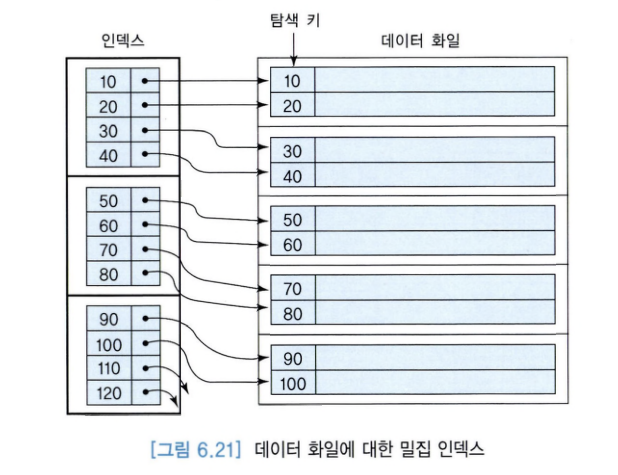

7. 희소 인덱스와 밀집 인덱스의 비교
| 희소 인덱스 | 밀집 인덱스 |
| 데이터 블록마다 한 개의 엔트리를 가짐. | 각 레코드마다 한 개의 엔트리를 가짐. |
| 인덱스 단계수가 일반적으로 밀집 인덱스보다 1정도 작음. 디스크 접근 수가 1만큼 적을 수 있음. |
인덱스 단계수가 희소 인덱스보다 1정도 큼. |
| 모든 갱신, 질의에 대해 효율적 | 인덱스가 정의된 애트리뷰트만 검색하는 경우, 인덱스만 접근해 질의를 수행할 수 있으므로 밀집 인덱스가 더 유리. |
한 화일은 한 개의 인덱스와 다수의 밀집 인덱스를 가질 수 있음.
8. 클러스터링 인덱스와 보조 인덱스의 비교
- 클러스터링 인덱스는 희소 인덱스일 경우가 많음. 범위 질의에 좋음.
- 보조 인덱스는 밀집 인덱스이므로, 일부 질의에 대해서는 화일을 접근할 필요 없이 처리 가능.
6-6 다단계 인덱스
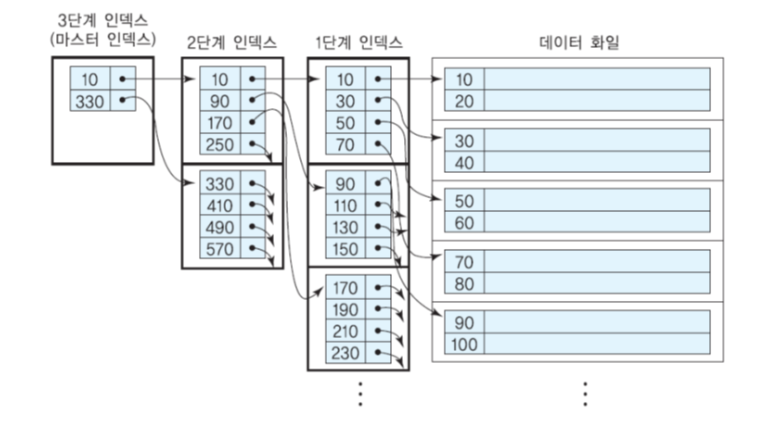
1. 다단계 인덱스
- 인덱스 자체가 클 경우 인덱스 탐색 시간도 오래 걸릴 수 있음.
- 탐색 시간을 줄이기 위해 단일 단계 인덱스를 디스크 상의 하나의 순서 화일로 간주해, 단일 단계 인덱스에 대해 다시 인덱스를 정의할 수 있음.
- 가장 상위 단계의 모든 인덱스 엔트리들이 한 블록에 들어갈 수 있을 때까지 반복함.
- 가장 상위 단계 인덱스를 마스터 인덱스라고 부름.
- 마스터 인덱스는 주기억 장치에 상주할 수 있음.
- 대부분의 다단계 인덱스는 B+- 트리를 사용.
2. SQL 인덱스 정의문
- SQL의 CREATE TABLe문에서 PRIMARY KEY로 명시한 애트리뷰트에 대해서는 자동으로 기본 인덱스가 생성됨.
- UNIQUE로 명시한 애트리뷰트에 대해서는 자동으로 보조 인덱스가 생성됨.
- 다른 애트리뷰트에 인덱스를 정의하려면 CREATE INDEX문을 사용해야 함.
3. 다수의 애트리뷰트를 사용한 인덱스 정의
- 한 릴레이션에 속하는 여러 애트리뷰트들의 조합으로 하나의 인덱스를 정의할 수 있음.
ex. CREATE INDEX EmpIndex ON EMPLOYEE (DNO, SALARY);
- 인덱스가 정의된 두번째 이후의 애트리뷰트만을 참조하는 WHERE절의 프레디키트를 만독하는 레코드를 찾기 위해서는 사용 불가함.
ex. SELECT *
FROM EMPLOYEE
WHERE SALARY>=200;
4. 인덱스의 장점과 단점
- 장점: 소수의 레코드들을 수정하거나 삭제하는 연산의 속도는 향상됨. 특히 릴레이션이 매우 크고, 질의에서 릴레이션의 튜플들 중에 일부를 검색하고, WHERE절이 잘 표현되었을 때 도움됨.
- 단점: 인덱스를 저장하기 위한 공간이 추가로 필요하고, 삽입, 삭제, 수정 연산 속도 저하.
6-7 인덱스 선정 지침과 데이터베이스 튜닝
1. 인덱스를 결정하는데 도움이 되는 지침
- 기본 키는 클러스터링 인덱스를 정의할 훌륭한 후보
- 외래키도 인덱스를 정의할 중요한 후보
- 한 애트리뷰트에 들어 있는 상이한 값들의 개수가 거의 전체 레코드 수와 비슷하고, 그 애트리뷰트가 동등 조건에 사용되면 비 클러스터링 인덱스를 생성하는 것이 좋음.
- 튜플이 많이 들어 있는 릴레이션에서 대부분의 질의가 검색하는 튜플이 2~4% 미만인 경우 인덱스 생성
- 자주 갱신되는 애트리뷰트에는 인덱스를 정의 안하는 것이 좋음.
- 갱신이 빈번한 릴레이션에는 인덱스를 많이 만드는 것을 피함.
- 후보키도 인덱스를 생성할 후보
- 인덱스는 화일의 레코드들을 충분히 분할할 수 있어야 함.
- 정수형애트리뷰트에 인덱스 생성
- VARCHAR형에는 인덱스를 생성하지 않음.
- 작은 화일에는 인덱스 필요 없음.
- 대량의 데이터를 삽입할 떄는 모든 인덱스 지우고 새로 만드는 것이 좋음.
- ORDER BY절, GROUP BY절에 자주 사용하는 애트리뷰트는 인덱스 후보.
2. 언제 인덱스가 사용되지 않는가?
- 시스템 카탈로그가 오래 전의 데이터베이스 상태를 나타냄.
- 질의 최적화 모듈이 릴레이션의 크기가 작으면 인덱스가 도움이 안됨.
- 인덱스가 정의된 애트리뷰트에 산술연산자가 사용될 때.
- 내장 함수가 사용될 때.
- 널값에 대해서.
3. 질의 튜닝을 위한 추가 지침
- DISTINCT절 사용 최소화
- GROUP BY절과 HAVING절 사용 최소화
- 임시 릴레이션 사용 피하라.
- SELECT * 대신 애트리뷰트 이름을 구체적으로 명시.
'Computer Science > DataBase' 카테고리의 다른 글
| [데이터베이스] 8장 뷰와 시스템 카탈로그 (0) | 2023.12.12 |
|---|---|
| [데이터베이스] 7장 릴레이션 정규화 (0) | 2023.12.12 |
| [데이터베이스] 5장 데이터베이스 설계와 ER모델 (2) (0) | 2023.11.26 |
| [데이터베이스] 5장 데이터베이스 설계와 ER모델 (1) (0) | 2023.11.25 |
| [데이터베이스] 4장 관계 대수와 SQL (0) | 2023.11.03 |



