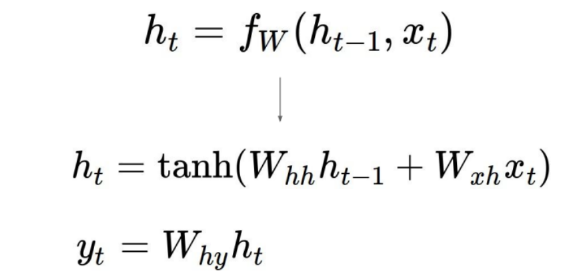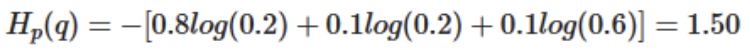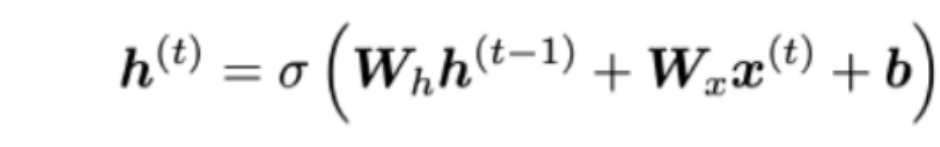Supervised Learning: 감정 분석, 기계 번역, 코드 생성, 요약, 질의 응답
2. NLP: a two-stage approach
Unsupervised Learning: Large Corpus 등의 dataset으로 Language Modeling을 수행
Supervised Learning: unsupervised로 가공한 dataset으로 Classification, Regression, Language Generation 등을 수행
3. Language Modeling
Language Modeling: 다음 순서에 어떤 단어가 올 지 예측하는 모델링.
식으로 나타내면 아래와 같다. 왼쪽에 있는 t개의 단어들을 가지고 t+1번째의 단어를 예측하는 것!
또한 단어에 확률을 부여하는 것이라고도 볼 수 있다.
4. N-gram Language Model
Markov assumption: x^(t+1)은 오직 n-1 단어들에만 의존해 예측한다.
(현재 상태가이전의 유한한 고정된 상태의 수에만 의존)
Markov assumption
n-gram: chunk of n consecutive words
n-gramexample
⚠️ N-gram model의 문제점 (Sparsity Problems)⚠️
[충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제]
Problem1. 만약에 "students opend their w"라는 문장이 나온 적이 한 번도 없으면 어떡하냐!
→ Sol: 모든 count에 매우 작은 값을 넣어서 probablity가 0이 되지 않게 하자. "Smoothing"
Problem2: 만약에 "students opend their"라는 문장이 나온 적이 한 번도 없으면 어떡하냐!
→ Sol: 그냥 "opened their"로 대체하자. "Backoff"
Problem3: Increasing n or Increasing corpus는 모델 사이즈를 키운다..
Problem4: 일관성이 없어진다. 전체 문장의 일관성을 n개의 단어로 예측하는 것은 일관성이 없다..
Note: n의 값이 커질 수록 sparsity 문제는 심해진다. n은 5를 넘기지 말자~
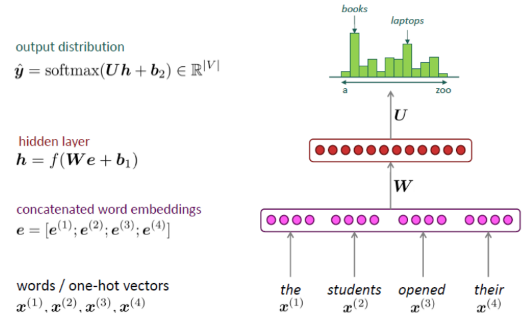
5. A fixed-window Neural Language Model
How about a window-based neural model?
해결
Sparsity 문제 해결
n-gram에 대해 모두 저장할 필요가 없음
문제
fixed window는 너무 작다.
window를 키우면 W의 값도 함께 커진다.
x1과 x2는 완전히 다른 가중치를 갖고, input 처리되는데 symmetry가 없다.(?)
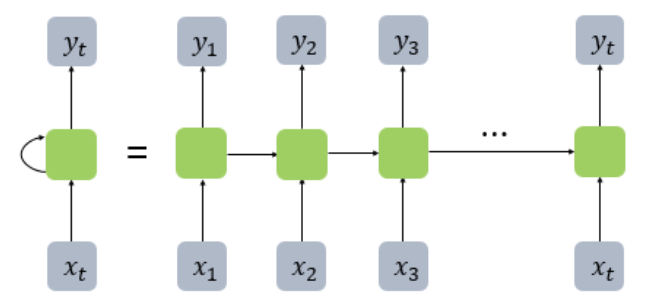
6. Recurrent Neural Networks(RNN)
Key idea: Apply the same weights W repeatedly
RNN 구조와 RNN 기본 식
RNN은 직전의 old hidden state와 해당 단계에서의 input vector를 가지고 새로운 state를 만든다!
아래는 이를 자세히 그린 그림이다.
내가 생각했을 때는 이 그림이 가장 잘 RNN을 표현하는 것 같다!!
식으로 표현을 하면 아래와 같다.
RNN의 장점
어떤 길이의 입력이든 처리 가능.
여러 단계 이전의 정보를 사용해 t 단계 계산을 할 수 있다.
모델 사이즈가 커지지 않는다.
같은 가중치를 적용해 symmetry가 있다.
RNN의 단점
Recurrent 계산이 느리다.
많은단계 이전의 정보를 사용하는 것이 어렵다.
RNN != Language Model
RNNs are great way to build a LM
7. Training RNN-based Language Models
Loss Function: 예측된 확률분포 y^와 실제 다음 단어 확률분포 y 사이의 Cross Entropy
여기서 잠깐! 나처럼 Cross Entropy가 기억이 안나는 사람들을 위해 정리를 한다면, 아래와 같은 식으로 계산된다. 여기서 q(xi)는 예측한 확률분포이고, p(xi)는 실제 확률분포이다. 예측을 잘 할 수록 q(xi)logp(xi)의 합이 커진다! 하지만 우리는 이를 loss로 사용할 것이므로 앞에 마이너스를 붙여 값이 작아지는 방향으로 학습 하고자 한다!
예를 들어, 가방에 0.8/0.1/0.1 의 비율로, 사과/자두/딸기가 들어가 있다고 하자, 하지만 직감에는 0.2/0.2/0.6의 비율로 들어가 있을 것 같다. 이 때의 cross-entropy 는 아래와 같이 계산된다.
아래는 또 다른 예제이다.
다시 위의 식으로 가겠다.
일단 여기까지는 쉽게 이해할 수 있을 것이다.
근데 왜 위처럼 -log y^^(t)x(t+1)로 되는 것이냐하면!
예측한 확률분포 y^(t)는 아래와 같은 형태로 나올 것이다.
그리고 실제 정답인 y(t)는 {0, 1, 0, 0, 0 ...}의 형태로 정답에만 1인 one-hot encoding되어 있을 것이다.
따라서 -log(정답에 해당하는 단어의 확률)이 되는 것이당!!
그래서 아래와 같이 Loss가 계산되는 것이다.
However, loss와 gradient를 계산하는 것은 too expensive하다.
▶ Stochastic Gradient Descent는 loss와 gradient를 계산할 때 작은 데이터로부터 계산 가능하게 한당
8. Generating with an RNN language model
repeated sampling을 통해 RNN도 text 생성에 사용할 수 있다!
9. Evaluating language models
학습에 쓰이지 않았던 자료로 test!
언어 모델 평가 지표는 보통 perplexity이다.
perplexity에 대해 몰라서 조금 찾아 봤다.
perplexity는 (무언가를 이해할 수 없어) 당혹스러운 정도, 헷갈리는 정도라는 사전적 의미가 있다. 보통 perplexity가 낮을수록 언어모델이 우수하다고 평가된다.
코퍼스에 대한 확률들을 inverse하는 것인데 이는 사실 cross-emtropy loss J를 exponential한 값과 동일하다고 한다.
10. Problems with RNNs
곱해지는 값이 1보다 크면 Exploding Gradient(NAN, inf) 문제가,
곱해지는 값이 1보다 작은면 Vanising Gradient(0) 문제가 생길 수 있다.
Vanishing gradient문제!
멀리 있는 gradient가 반영이 잘 안된다!
Q. 그렇다면 이 문제를 어떻게 해결할 수 있을까?
RNN에서는 hidden state가 지속적으로 재작성된다.
해결: 별도의 메모리를 가지고 있는 RNN
→ LSTM
해결: 추가적인 기술
→ Attention, residual connection...
Q. Exploding gradient가 왜 문제일까?
gradient가 너무 커지면, SGD(Stochastic Gradient Descent) 업데이트가 너무 커진다!