7장 Language Model에서 어시스턴트로의 발전(언어모델의 3단계)
1. Pretraining: In-context Learning
- 장점1: 추가 학습 없이, 프롬프트엔지니어링(ex.CoT)으로 성능향상 가능.
- 단점1: 맥락에 담을 정보의 양에 한계가 있음.
- 단점2: 복잡한 task에서는 어느정도 gradient step이 필요.(fine tunning)
GPT는 pretrained model!
BERT는 수만개의 데이터로, GPT는 few-shot으로 학습하는데 성능 비슷함.
Chain-of-thought prompting(사고의 사슬) - ex. 수학 문제 예제를 줄 때 풀이과정도 함께 줌.
"Let's think step by step"과 갗은 문장을 넣어주니 성능이 더 좋아짐.
2. Instruction Finetuning
- 장점1: 보지 못했던 task에 일반화 가능.
- 단점1: demo 데이터 모으는데 많은 비용이 듦.
- 단점2: 언어 모델과 인간의 선호도 사이의 불일치가 있을 수 있음.
- 단점3: 모든 토큰에 대한 실수를 동일하게 처벌함.
- 단점4: 창의적인 생성 task에는 right answer가 없음.

1번(pretraining)에서는 그냥 train된 모델을 바로 사용,
2번(instruction finetuning)에서는 몇가지 예제를 collecting해서 학습(finetune)시키고, unseen task로 평가.
기존에는 하나의 모델은 하나의 task만 해야 한다고 생각함.
근데! GPT가 나오면서 이 생각이 바뀜. + → fine tuning해서 특정 작업을 잘 하도록!
가장 유명한 테스트 데이터셋 - MMLU(Massive Multitask Language Understanding)
얼마나 잘 암기 했는가를 확인
3. Optimizing for Human Preference(DPO, RLHF)
- 장점1: 인간의 선호도를 직접 모델링하고, 레이블 없는 데이터에도 일반화 가능.
- 단점1: 강화학습이 제대로 수행되기 어려움
- 단점2: 사람의 선호도는 불완전함. (인종별, 나라별 등 평가 기준에 따라 우위가 다를 수 있음.)

(1) RLHF(Reinforcement Learning from Human Feedback)

😥기존 문제1: human-in-the-loop은 비싸다!
해결1: 선호도 묻지말고 NLP문제로 모델링 하자!
→ 인간의 reward를 예측하는 reward model을 훈련하자!
사람이 모든 output에 대해 평가하는 것은 힘드니까 몇 개만 평가하고,
그걸 가지고 Reward 모델을 만듦.
그러면 사람이 선호도를 평가할 이 다양한 응답 샘플링을 어떻게 만드냐!!
→ Scaled Probabilities!! - temperature를 사용하여 응답을 다양하게 만듦!!
t가 커지면 더 다양한 값이 나옴.

😥 기존 문제2: 사람의 판단에는 noise가 있다!
해결2: 직접 rating을 묻지 말고 pairwise comparison(쌍별 비교)을 묻자!!winning sample에 대한 reward는 커지고,
losing sample에 대한 reward는 낮아지는 방향으로 학습.


좀 더 수식적으로 알아보자.
최적화하고자 하는 파라미터 θ를 가진 pretrained model을 가져와 아래의 식을 최적화 한다.

여기서 결과가 pretrained model과 너무 멀리 벗어나는 것을 방지하기 위해 페널티를 추가한다.
이를 Kullback-Leibler(KL) divergence 값이라고 한다.
베타로 Reward Model과 Pretrained Model의 학습 비율을 정한다.

(2) DPO(Direct Preference Optimization)
RLHF에서 좀 더 단순화할 수 없을까..?
언어 모델뿐만아니라 보상 모델도 학습시켜야 해서 번거로움..
따라서 DPO에서는 보상 모델을 안씀!
RLHF의 동작과정 요약:
Reward model을 학습시켜, 스칼라 값인 보상을 생성.
Reward model과 Pretrainded model을 최적화해 Reinforce Learning model 생성.
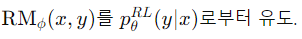



- RLHF: 전체 보상을 최대화하고, 모델이 사전 학습된 상태로부터 너무 벗어나지 않도록 함.
- -> 조금의 선호도 데이터를 가지고 학습하는 reward model을 사용!!
- DPO: 두 개의 출력(선호되는 것과 덜 선호되는 것)을 비교하여 모델을 직접 학습합니다.
- -> 그냥 조금의 데이터로만 pairwise comparison해서 맞는 방향으로 학습

'Computer Science > Deep Learning Application' 카테고리의 다른 글
| [딥러닝] 10장 컴퓨터 비전, Conv와 멀티모달 학습 (0) | 2024.06.15 |
|---|---|
| [딥러닝] 9장 최근 언어 모델 (0) | 2024.06.14 |
| [딥러닝] 8장 Generalization과 Evaluation (0) | 2024.06.09 |
| [딥러닝] Subword Tokenizer (0) | 2024.04.10 |
| [딥러닝] 4장 NLP&RNN&LSTM (0) | 2024.04.04 |


