Hard Sample Aware Network for Contrastive Deep Graph Clustering
Yue Liu et al. NIPS 2020
c. https://arxiv.org/pdf/2212.08665
https://github.com/yueliu1999/HSAN
Abstract
hard sample minig method에는 2가지 문제점이 있고, 우리는 이 문제점들을 해결하는 방법인 HSAN을 제안한다.
😨Problem1. 유사성 계산에서 중요한 구조적 정보가 간과됨.
→ Sol. 새로운 유사성 측정 기준 도입! (considering attribute embedding and structure embedding)
😨Problem2. 어려운 부정 샘플에만 초점을 맞춤. 어려운 긍정 샘플 무시.
→ Sol. 가중치를 동적으로 증가, 감소시키면서 어려운 긍정샘플 발굴!
HSAN(Hard Sample Aware Neatwork)
Methods

(1) Attribute and Structure Encoding
AE1, AE2, SE1, SE2는 모두 MLP


새로운 유사성 척도 도입!

(2) Clustering and Pseudo Label Generation
K-means clustering 진행
→ P: 전체 N개 의 노드에 대한 pseudo label을 구함.
→ H: M개 high-confidence smaple을 뽑아냄.
→ Q: pair psudo label을 계산함. (N X N, 0이면 neg, 1이면 pos.)
(3) Hard Sample Aware Contrastive Learning
classi-cal infoNCE loss

동일한 샘플은 다른 뷰에서 서로 가깝게 모음.
이 classical infoNCE의 문제점!: hard sample과 easy sample을 동일하게 다룸.
→ Sol: weight modluation function M을 제안한다!
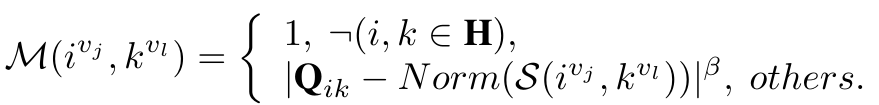
이 M은 가중치 역할을 한다!
1) M can up-weight the hard samples while down-weighting the easy samples.
만약 H에 들어있으면서, Q = 1일 때, 즉 긍정 sample일 때를 고려해보자.
우리는 Similarity가 높을 수록 쉽게 묶을 수 있다.
만약 긍정의 hard sample이면 긍정임에도 불구하고 S가 작을 것이다.
그러면 M값은 증가하게 된다. -> hard sample 가중치 up!
<예시>
- Q = 1(긍정 샘플), B = 2라고 하자.
- case1) 쉬운 긍정 샘플. S = 0.90일 때, M = (1-0.09)^2 = 0.01
- case2) 어려운 긍정 샘플. S = 0.10일 때, M = (1-0.10)^2 = 0.81
- 따라서 어려운 긍정샘플에 더 초점을 맞추고 학습을 할 수 있다!!
2) B contols the down-weghting rate of easy pairs.
<예시>
- Q = 1(긍정 샘플)
- 쉬운 긍정 샘플에서 S = 0.90일 때,
- B가 1이면, M = (1-0.90)^1 = 0.1
- B가 3이면, M = (1-0.90)^3 = 0.001

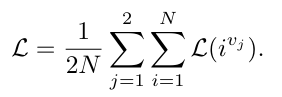
(4) Complexity Analysis of Loss Funcion
궁금한 점..
왜 High Confidence에 있는 sample에 가중치를 저장하는 것이 아닐까..?
240530 16:00 미팅 기록
hard sample? -> similarity 찾기 어려운 애들
한번 Ev1과 Ev2를 찍어봐랏
'연구 > 논문' 카테고리의 다른 글
| [미팅 후 기록] What Makes for Good View for Conrastive Learning? (NIPS 2020) (0) | 2024.05.29 |
|---|---|
| [논문정리, 미팅기록] What Makes for Good View for Conrastive Learning? (NIPS 2020) (0) | 2024.05.23 |

