0. Overfitting
- training 데이터와 다른 값들이들어오면 loss가 커짐.
- generalization과 반대!
1. Regularization techniques
- generalization하게 만들기 위한 방법들의 집합.
9-1 Explicit regularization
1. Explicit regularization


- g[ϕ]: 매개변수가 덜 선호될 때 큰 값을 반환하는 스칼라를 반환하는 함수.
- 어떤 매개변수를 덜 선호하도록 유도
- λ: 원래 손실 함수와 정규화 항의 상대적인 기여를 제어하는 양의 스칼라.

- a) Gabor모델의 손실함수
- b) 중심에서 멀어질 수록 증가하는 패널티를 추가해 매개변수가 중심에 가까워지도록 유도
- 최종 손실함수는 원래 손실함수 + 정규화 항의 합
2. 확률적 해석
- 기존의 최대 우도 기법에서 사전 확률을 고려해 파라미터를 조정한다고 생각할 수 있음!


- negative log-likelihood loss적용

3. L2 regularization
- 그렇다면 어떤 솔루션에 대해 패널티를 주어야하는가!
- 파라미터 값의 제곱의 합에 패널티 부여.
- = tikhonov regularization = ridge regression = frobenius norm regularization

4. 가중치 감소
- L2정규화는 bias에는 적용되지 않고, 가중치에만 적용되어 weight decay라고 함.
- 더 작은 가중치를 촉진해 출력 함수를 부드럽게 만듦.


5. 성능을 향상시키는 두 가지 이유
- 학습데이터에만 절대적으로 따르려는 것과 smoth해지는 욕망 모두 작동 (모델은 꼭 모든 데이터 포인트를 지나가려고 하지 않아도 됨.)
- over-parameterized된 모델은(정규화 항이 추가된) 훈련데이터에만 지나치게 의존하지 않고 새로운 데이터를 더 잘 학습.
9-2 Heuristices to improve performance
1. Early stopping
- 완전히 수렴하기 전에 훈련을 멈추는 것.
- val_data의 성능이 T 반복마다 한번씩 저장됨.
- (c)나 (d)에서 early stop됨.

2. Ensemble
- 여러 모델들을 구축하고 그들의 예측을 평균화.
- 이런 모델 그룹을 Ensemble이라고 함.
- 회귀 문제 - 모델 출력의 평균/ 출력의 중앙값
- 분류 문제 - pre-softmax 활성화의 평균/ 가장 빈번하게 예측된 클래스
- 가정: 모델의 오류가 독립적이고, 상쇄될 것.
- 그렇다면 어떻게 여러 모델을 만들지!?
- (1) 서로 다른 랜덤 초기화를 사용. - 초기 가중치 무작위 초기화.
- (2) boot strap aggregation. - 훈련 데이터를 복원 추출해 서로 다른 데이터셋을 생성하고, 다른 모델 훈련.
- (3) 서로 다른 하이퍼파라미터로 모델 훈련시키기
- (4) 완전히 다른 종류의 모델을 훈련시키기

3. Dropout
- SGD의 각 반복에서 hiddden 유닛의 일부를 무작위로 제거.
- 모델이 특정 hidden 유닛에 의존하지 않도록 유도.


- 그렇다면 테스트는 어떻게 하냥!
- (1) The weight scaling inference rule
- 모든 은닉 유닛을 활성화해 평소처럼 학습시킴.
- 그러나 훈련에서보다 더 많은 은닉 유닛이 있으므로 가중치에 (1-(dropout 확률))을 곱해준다.
- (2) Monte Carlo dropout
- 무작위로 선택된 은닉 유닛의 부분 집합을 활성화시킴.
4. Applying noise
(1) input에 노이즈 추가

(2) weight에 노이즈 추가
가중치를 작은 변화에도 합리적인 예측을 하도록 격려. 가중치에 덜 민감해짐.
훈련은 가중치가 크게 바뀌어도 중요하지 않은 넓고 평평한 영역의 로컬 최소값으로 수렴 ? ? ?

(3) label에 노이즈 추가
정답에 대해서는 높은 확률, 정답이 아닌 레이블에 대해서는 작은 비슷한 확률들 부여.
훈련 반복에서 레이블을 무작위로 변경하므로서 실현.

5. Transfer learning and multi-task learning
train data가 제한적이 경우 다른 데이터 셋을 활용!
(1) 전이 학습
- primary task에 대해서는 제한된 레이브 데이터가 있지만, secondary task에는 풍부한 데이터가 있는 경우 사용.
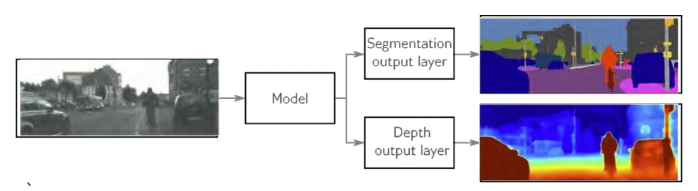
- 아래의 그림에서 Depth는 primary task이고, Segmention이 secondary task이다.
- Segmentation 모델을 훈련하고 최종레이어만 제거하고 Depth 레이어로 교체한다.
- 그 뒤 전체 모델에 대해 fine-tuning한다.

(2) 멀티 테스크 학습
- 하나의 모델이 여러 작업을 동시에 학습하도록함.
- 동시에 학습되면 각 작업에 대한 모델 성능이 향상.
6. Self-supervised learning
- Generative self-supervised 학습
- 자신의 데이터의 일부를 제거하고 이를 완성하도록 학습시킴.
- 이미지의 경우, 구멍 뚫어놓고.
- 텍스트의 경우 단어 누락.
- Contrastive self-supervised learning
- 공통점이 있는 예제 쌍과 무관한 쌍과의 비교.
- 이미지의 경우, 두 이미지가 서로의 변형 버전인지 또는 서로 무관한지를 식별
- 텍스트의 경우, 두 문장이 원래 문서에서 이어지는 것인지를 결정
7. Augmentation
- 데이터 증강: 추가 훈련 데이터를 생성
- 이미지의 경우, 회전, 뒤집기, 흐리게 하거나 색상 균형을 조작.
- 동의어로 대체하거나 다른 언어로 번역하고 다시 번역.

1. Regularization은 손실함수에 항을 추가해 최솟값의 위치를 변경하는것.
2. 이 용어는 사전 확률로도 해석됨.
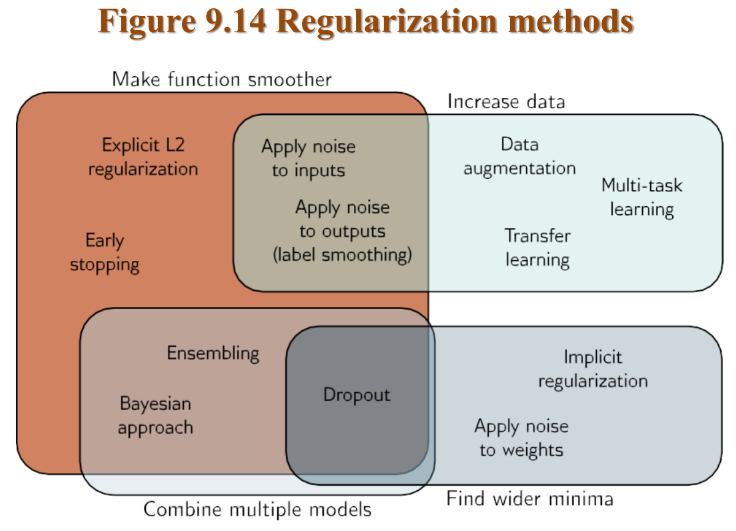
3. 일반화를 향상시키기 위한 여러 휴리스틱이 존재함.
얼리 스톱핑 • 드롭아웃 • 앙상블 • 베이지안 접근법 • 노이즈 추가 • 전이 학습 • 멀티태스크 학습 • 데이터 증강
'Computer Science > Artificial Intelligence' 카테고리의 다른 글
| [인공지능] SP06. Fitting Models (0) | 2023.11.08 |
|---|---|
| [인공지능] SP05. Loss functions (0) | 2023.10.21 |
| [인공지능] SP04. Deep neural networks (0) | 2023.10.18 |
| [인공지능] SP03. Shallow neural networks (0) | 2023.10.18 |
| [인공지능] 6장/ 7장/ 8장 (2) | 2023.10.17 |



