Topic-Specific Page Rank
Some problems with page rank:
페이지 랭크가 가지고 있는 몇가지 단점은 아래와 같다!
- 너무 일반적인 popularity를 측정함.
- 이는 그냥 권위있는 페이지가 짱임.
- ex. apple을 검색했을 때 사과, 회사 처럼 다양하게 나오도록 못함
- 중요성을 측정하는 단일 지표만 사용.
- 다른 모델의 예: hubs and authorities가 있음
- link spam에 취약
- 인공적인 링크가 만들어져서 페이지 랭크를 조작하는 것이 가능함.
Topic-Specific Page Rank:
generic한 인기 대신, 하나의 주제 내에서의 인기를 측정할 수 있다.
Bias the random walk
: 랜덤 워커가 이동할 때 특정 집합 S의 웹페이지에서 페이지를 선택!
S에는 해당 주제와 관련된 페이지만 포함!
→ 각 집합 S마다 다른 랭크 벡터 rs가 존재한다.
원래 기존의 페이지랭크에서는 아래와 같이 A를 정의했다면,

Topic-Specific Page Rank에서는 아래와 같이 A를 정의한다.

i 2 S 는 i가 S에 포함된다는 뜻이다. 만약 포함이 안 된다면, 아래와 같다

A는 stochastic하다. -> 외부에서 추가도, 빠져나감도 없다.
예를 들면 아래와 같다.

- S set에 1번 노드만 포함되어있고, B 베타가 0.8이라고 하자.
- 파란색 글씨가 행렬 M에 적힌 값임.
- iteration0: 초기에 1번 노드만 1만큼 가지고 있음
- iteration1: S에 1번 노드만 있고, 베타가 0.8이므로, 1번노드는 0.2만큼 teleport를 받음. 2번 3번 노드는 파란색대로 0.8의 절반씩 가져감.
- iteration2:
- 노드 1번: 0.4*0.8 + 0.2 = 0.52 (노드 2번이 준 만큼*0.8 + teleport로 받은 0.2)
- 노드 2번: 0.1*0.8 = 0.08 (노드 1번이 준 만큼*0.8)
- 노드 3번: 0.1*0.8 = 0.08 (노드 1번이 준 만큼*0.8)
- 노드 4번: 0.4*0.8 = 0.32 (노드 3번이 준 만큼*0.8)
- 결과가 stable해진 값을 보면 3번 노드가 가장 중요하다는 것을 알 수 있다.
- 일반적인 페이지 랭크와 달리 TSPR에서는 랭크 벡터를 초기화하는 방법이 다름!
TSPR is good?:
✔️ TSPR이 얼마나 효과적인가?
TSPR 했을 때가 안 했을 때보다 rank score 퀄리티가 더 좋아보이는지 blind test하니까 사람들이 TSPR을 더 선호!
✔️어디서 사용해야 할까?
쿼리의 맥락, 이력, 사용자 컨텍스트를 고려할 수 있음.
Hubs and Authorities
HITS(Hypertext-Induced Topic Selection):
넓은 주제의 문서 모음이 주어졌을 때를 생각해보자.
이떄 랭킹을 어떻게 맥일거야?라는 의문의 해결법이 HITS!
HITS를 사용하려면 잘 연결된 그래프가 필요하다.
HITS를 알려면 아래의 두 개념을 알아야 함.
1️⃣ Authorities: 유용한 정보를 포함하는 페이지, Hub score < Authorities score
2️⃣ Hubs: authorities 페이지를 링크하는 페이지, Hub score > Authorities score
상호 재귀적 정의
- 좋은 hubs는 많은 좋은 권위를 링크.
- 좋은 authorities는 많은 좋은 허브로부터 링크를 받음.
페이지 랭크에서 사용한 행렬 M대신, HITS에서는 행렬 A를 사용.
A[[i,j]는 i 페이지와 j 페이지가 연결되어 있으면 1, 아니면 0임. M은 1 자리에 분수값들이 들어있었음

Hub score and Authority:
Hub score

Authority score
여기서 저 람다랑 u는 그냥 상수임.
구하는 방법!

또한 아래처럼 쓸 수 있다.
이렇게 쓰고, 최종적으로 수렴하는 값들을 h*와 a*라고 했을 떄 각각은 아래처럼 eigenvector가 될 수 있다.

Bipartite cores: #############여기 잘 모르겠다###############
웹 페이지 상에서 dense한 부분을 primary core, secondary core라고 하자!
- eigenvalue는 코어 내 링크의 밀도를 나타냄.
- eigenpair - 동일한 eigenvalue를 가진 eigenvector 쌍
- primary eigenpair - 아래의 반복 알고리즘에서 얻는 것
- Non-primary eigenpair - 다른 이분 그래프 코어에 상응 ..?
Secondary core를 어떻게 하면 찾을 수 있을까?
- primary core를 찾은 후, 링크를 그래프에서 제거한다.
- 남은 그래프에 HITS 알고리즘을 반복하여 다음 bipartite coore를 찾는다.
Spam Detection
Web Spam:
<Spamming 관련 용어>
- Spamming: 페이지의 가치를 높이려고 하는 고의적인 행동
- Spam: spamming의 결과 나오는 페이지.
- Reptition: TF.IDF(Term Frequency, Inverse Document Frequency)를 왜곡하기 위해 특정 용어를 반복.(ex. 무료, 싸게 ..)
- Dumping: 관련 없는 용어 대량 삽입
- Weaving: 랜덤한 자리에 spam term 삽입
- Phrase Stitching: 서로 다른 source에서의 문장을 붙임.
<Web Spam 분류> - Gyongyi and Garcia-Molina
- Boosing techniques: 웹 페이지의 높은 관련성을 달성하기 위한 기술
- Term spamming: 쿼리랑 관련있는 것처럼 텍스트를 조작하는 것
- Link spamming: 텍스트를 바꾸지는 않지만 link 구조를 이상하게 만드는 것(hub, auth score 높임)
- Hiding techniques: Boosting techniques 사용을 숨기기 위한 기술
Link Spam:
스코어를 구하는 식에 링크를 맞추는 것.
<Spammer의 관점에서의 웹페이지 종류>
- 접근할 수 없는 페이지
- 접근 가능한 페이지 - spammer는 자신의 페이지에 링크할 수 있음.
- 자체 페이지 - spammer가 완전 제어하는 페이지
<Spammer의 목표>
대상 페이지 t의 페이지 랭크 극대화 하기!!
<Technique>
- 접근 가능한 페이지들에 타겟 페이지 t로 가는 링크를 심어두기
- 페이지 랭크의 multiplier 효과를 얻기 위해 "Link Farm" 구축하기
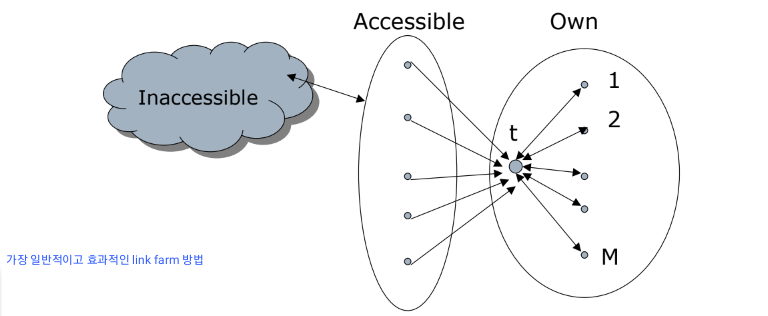
한 번 분석을 해보자!
x = 접근이 가능한 페이지
y = target페이지의 page rank
M = farm 페이지의 수
N = 전세계에 있는 페이지 수
y를 구하면 아래와 같다.
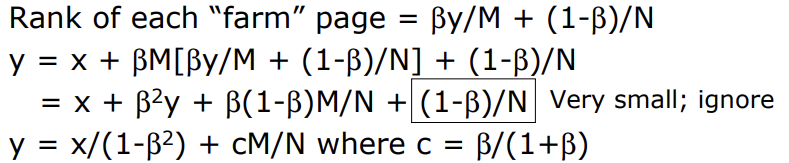
따라서!! M의 수가 커질수록 y의 page rank도 함께 커진다.
Detecting Spam:
스팸을 어떻게 탐지 하냐!
- Term spamming
- 통계적 방법으로 텍스트 분석. ex. 나이브 베이즈 분류기(Naive Bayes Classifiers)
- 이메일 스팸 필터링과 유사
- 중복 페이지 탐지에도 유용
- Link spamming
- 많은 방법이 있음.
- 그 중 하나가 TrustRank
TrustRank idea:
- 기본 원칙: "대략적인 격리"
- "좋은" 페이지, "나쁜" 페이지 나누는건 어렵..
- 웹에서 Seed pages 집합을 샘플링한다.
- Seed set 내에서 좋은 페이지와 스팸 페이지를 식별하는 엔티티를 갖는다.
- 비용이 많이 드므로 Seed set은 작아야 한다.
- Seed set에서 "좋은"으로 분류된 하위 집합을 "trusted pages"라고 한다.
- 각 신뢰할 수 있는 페이지의 신뢰도를 로 설정.
- 링크를 통해 신뢰를 전파 -> Trust Propagation
- 각 페이지는 0~1 사이의 신뢰도를 가짐.
- 신뢰 임계값을 사용해 임계값 아래는 spam으로 표시
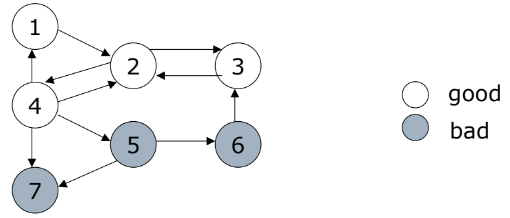
Trust Propagation의 규칙(2)
- Trust Attenuation(신뢰 감쇄) - 거리가 멀어지면 신뢰도도 함께 감소
- Trust Splitting(신뢰 분할) - outgoing link가 많을수록 각 링크에 대해 덜 신중해짐, 신뢰는 링크를 통해 분할

앞에서 말한 Seed set은 어떻게 선정하냐!!
아래의 두가지 고려사항이 있다.
- 인간이 각 seed 페이지를 검토해야하므로 seed set은 작아야 한다.
- 모든 "good page"가 충분한 신뢰 등급을 받도록, 모든 좋은 페이지가 seed set으로부터 짧은 경로로 도달 할 수 있어야 함.-> seed set은 커야 한다.
PageRank로 k개의 seed set 구하기:
PageRank가 가장 높은 상위 k개의 페이지를 선택.(높은 페이지 랭크를 가진 애는 다른 높은 페이지 랭크를 가진 페이지와 가까울 것임.)
Inverse PageRank로 k개의 seed set 구하기:
PageRank에서는 incoming link를 중요시했다면, Inverse에서는 outgoing link를 중요시해보자.
웹그래프에 있는 화살표 방향을 바꿔서 그래프 G'를 구성하자.
G'에서의 상위 k개의 페이지를 선택하자
Spam Mass:
어떤 웹페이지의 페이지 랭크 값이 스팸으로부터, 스팸이 아닌 페이지로 부터 들어온 비율 어케알아?!
-> Spam Mass라는 measure를 사용해 평가하자!

.edu, .gob, .mil 등의 사이트는 spam일 확률이 적다
'Computer Science > Web Information System' 카테고리의 다른 글
| [웹정보] ch06 Association Rules2 (0) | 2024.04.20 |
|---|---|
| [웹정보] ch06 Association Rules1 (0) | 2024.04.20 |
| [웹정보] ch05 Link Analysis1 (0) | 2024.04.15 |
| [웹정보] ch03 Finding Similar Items2 (0) | 2024.03.25 |
| [웹정보] ch03 Finding Similar Items1 (0) | 2024.03.15 |



