Market Baskets
우리는 basket 사이의 관계가 아니라 item 사이의 관계가 궁금하다!
Frequent Itemset:
itemset이 support threshold 값인 s 이상 나타나면 frequent itemsets이다!!

다른 예시들
- Item: 물건, basket: 구매한 물건들의 집합
- Item: 문서, basket: 문장
- 반대로 생각할 수도 있지만 사용하는 목적에 따라 다른 거임.
- 즉 counting의 대상이 item이 되는 것임
- 몇개의 문서가 해당 문장을 포함하고 있냐
- Item: 단어, basket: 웹페이지
- 단어로 아래와 같은 웹 마이닝을 할 수 있음
- 1. 페이지를 주제에 따라 클러스터화
- 유용한 블로그 찾기
- 댓글의 감정 판별
- 모호한 검색어로 검색된 페이지 분할 - ex. 재규어
Support:
n(X∪Y) / n(ALL)
TF/IDF
- stop word는 별로 중요하지 않아서 무시~
- TF/IDF (Term Frequency, Invese Document Frequency)
TF: 단어가 몇번 나오냐 / IDF: 단어가 몇개의 document에 있냐
-> TF는 높아야하고, IDF는 작아져야 함! -> TF/IDF
- TF/IDF 값이 낮으면 - 의미 없는 단어
- TF/IDF 값이 높으면 - 해당 문서의 주제일 수 있는 단어
Association Rules
Association Rules:
item 사이의 관계를 나타내는 법칙
Confidence(신뢰):
n(X∪Y) / n(X)

confidence가 높으면 좋은 rule임
해당 association의 support = (mb의 support)*(mb의 support에 confidence)
Finding Association Rules:
Q. suppport >= s 이고, confidence >= c인 모든 association rule을 찾아라!
(만약 높은 support 값과 confidence값을 가지고 있다면, 그 assosication은 frequent한 것이다)
Compuation model:

주로 드라이브의 I/O 수가 비용이 됨.
따라서 모든 바구니를 차례로 읽는 과정의 비용을 측정.
메인메모리 bottleneck 현상
Finding Frequent pair:
3중 pair는 많이 일어나지 않고, 더 느리게 증가하므로, 일단은 frequent pair에 집중하고 더 큰집합으로 확장하자!
Naïve Algorithm
n(n-1)/2개의 쌍을 생성해 메인 메모리에 올림.
(n^2개의 쌍을 올리는 것보다 겹치는 거 빼서 위처럼 쌍을 생성해서 메인 메모리에 올리면 좀 더 효율적)

Details of Main-Memory Counting
1️⃣ Triangular matrix를 사용해 모든 쌍을 센다
-> 모든 쌍이 메인메모리에 올라가므로 (4byte)*(모든 쌍의 수)
- 전체 쌍의 수는 n(n-1)/2이다.
- 전체 바이트는 2n^2이다. ########이해 안감#########
- {1,2}, {1,3}, ..., {1, n}, {2,3}, {2,4}, ..., {2, n}, {3,4}, ..., {3, n}, ..., {n-1, n}의 순서로 sorting
- (i-1)(n-i/2) + j - i에서 쌍 {i, j}을 찾음
2️⃣ 등장하는 쌍만 [i, j, c] 형태로 저장하자. i와 j가 같이 c번만큼 나왔다.
-> 만약 등장을 한번이라도 했으면 12byte, 등장하지 않았으면 0byte
- 검색을 위해 해시테이블을 사용해 추가적인 공간이 필요할 수도 있
→ 만약 등장하는 쌍이 전체의 1/3인 경우의 두 방법의 유용성은 같음!
→ 1/3 이하로 pair가 등장하는 경우는 2️⃣번 방법 이 더 유리.
A-Priori algorithm
A-Priori algorithm:
pair를 어떻게 하면 효과적으로 찾을 수 있을까?!
→ 전체 데이터를 2번 읽겠다!
→ monotonicity: 특정 아이템 집합이 최소 s번 나왔으면, s 안의 하위집합은 최소 s번 나타난다.
쌍의 대우 명제:
만약 아이템 i가 s개의 바구니에 나타나지 않았으면 → i를 포함하는 쌍은 s개의 바구니에 나타나지 않는다.
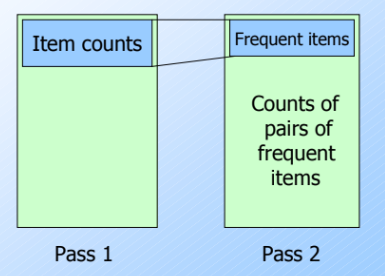
A-Priori algorithm - Pass
Pass 1
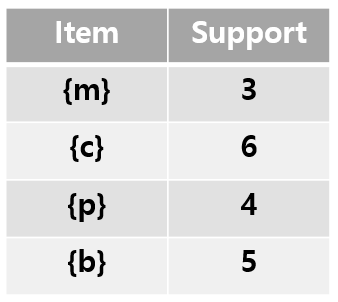
: basket을 읽고, 메인메모리에 각 아이템의 발생 횟수를 계산한다.
→ 아이템 수에 비례하는 메모리만 필요. (#items)
→ s 이상 나타나는 아이템은 "frequent items"
(1-frequent item까지만 찾고 다음 단계로)
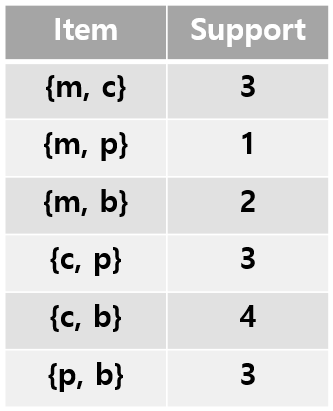
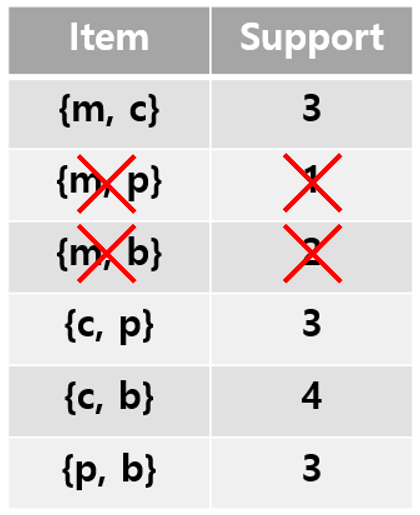
Pass 2
pass1에서 frequent하다고 판명 났던 두 아이템을 포함하는 셋만 counting!
→ (frequent 아이템 수)의 제곱에 비례하는 메모리만 필요.
Triangular & A-Priori algorithm:
여기에 triangular 방법을 사용할 수 있음.
대신 아래 그림처럼 새로운 id를 제
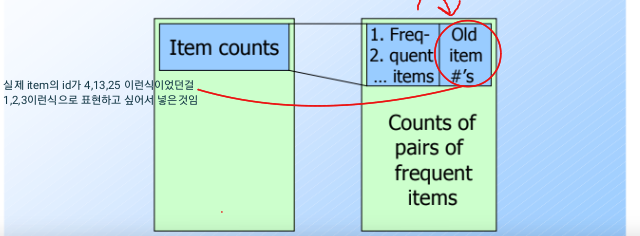
A-Priori algorithm의 일반화:
k = frequent한 셋 안의 원소 개수
Ck = candidate k-set 모음, k-1 패스에서 나온 frequent set 모
Lk = k-set 모음
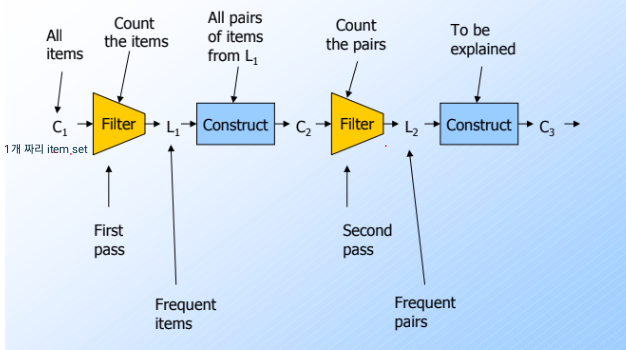
C1 = 개별 모든 아이템들의 쿼리
L1 = frequent items
C2 = 모든 페어가 들어있는 쿼리
L2 = frequent pairts
.
.
.
그림 출처
https://ddongwon.tistory.com/110
Association Rules(Support, Confidence, Lift, A-priori 알고리즘)
1. Association Rules Association Rules 란, items 사이의 관계를 나타내는 법칙을 찾는 방법이다. Association Ruels 에서 항상 나오는 예제가 바로 시장에서 물건을 사는 예제이다. 시장에 과일, 야채, 고기, 생
ddongwon.tistory.com
'Computer Science > Web Information System' 카테고리의 다른 글
| [웹정보] ch09 Recomeder Systems 1 (0) | 2024.06.10 |
|---|---|
| [웹정보] ch06 Association Rules2 (0) | 2024.04.20 |
| [웹정보] ch05 Link Analysis2 (0) | 2024.04.16 |
| [웹정보] ch05 Link Analysis1 (0) | 2024.04.15 |
| [웹정보] ch03 Finding Similar Items2 (0) | 2024.03.25 |



